Clusters management
Clusters selection
OKA can handle multiple clusters that have to be defined during OKA configuration.
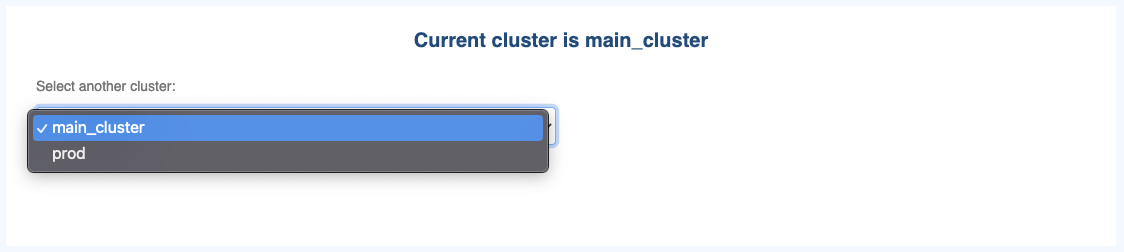
You can then choose the cluster you want to consider in OKA using the Clusters button on the left navigation bar.

This panel will allow you to select a cluster among all the ones available. All OKA plugins will then display the data for the selected cluster.
If you have only 1 cluster and did not define a cluster name during OKA configuration, it will be named main_cluster by default.
Administrator capabilities
If you are logged-in as an OKA administrator, you also have access to the following capabilities.
Create a cluster
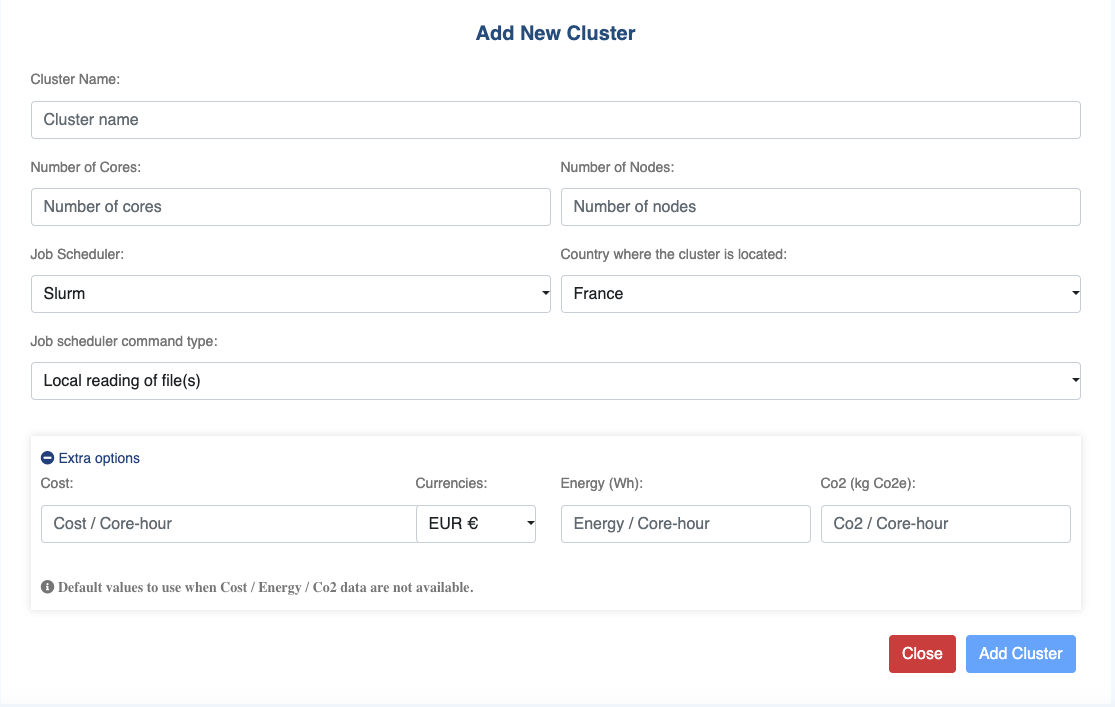
You can create new cluster with the create cluster button on the right side of the cluster list (blue “plus” button). You need to fill in the following mandatory fields:
Cluster Name: String
Number of Cores: Integer
Number of Nodes: Integer
Job Scheduler: [“Slurm”, “Open Grid Engine”, “LSF”, “PBS”, “Torque”, “OpenLava”]
Country where the cluster is located : You must select it from the list of countries.
The type of log ingestion:
LOCAL: Local job scheduler command executionFILE: Local reading of file(s)FORWARDED_PWD: Command execution remotely forwarded through SSH, login with a passwordFORWARDED_KEYFILE: Command execution remotely forwarded through SSH, login with an ssh key file
Job Scheduler connection settings:
These input fields will be active when the Job Scheduler type is set to:
Forwarded command execution (using password auth):Hostname,UsernameandPassword
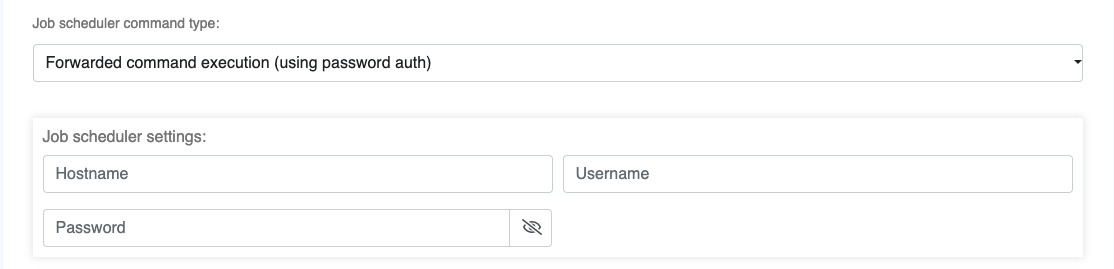
Forwarded command execution (using ssh key auth):Hostname,UsernameandKey Path
Hostname: Enter the hostname or IP address of the targeted host where you want to execute commands. For example, “example.com” or “192.168.1.100”.Username: Enter the username to be used to log in to the targeted host. This should typically be an account with the necessary permissions to execute the desired commands. For example, “myuser”.Password: Enter the password associated with the provided username. Ensure that this password is kept secure.Key path: Specify path to the SSH key you want to use for authentication. For example, “/path/to/ssh-key.pem”.
Warning
When using an SSH key, make sure this one does not require a passphrase to avoid any connection trouble.
Options:
Cost: Float
Energy: Float
CO₂: Float
Currency: You must select it from the list of currencies.
Note
Options are not mandatory. Cost, Energy and CO₂ are default values to be used to compute a substitute when data are not available in the database.
For example:
If the database contains 2 job defined as follows:
Job A has a value set in the
CostandEnergyfields but not in theCO₂field.Job B has no value set in any of the
Energy,CostandCO₂fields.And a Cluster C options defined as follows:
Cost= Null
Energy= 0
CO₂= 2
Then, when requesting data, the fields will be dealt with in the following way:
Cost:
For job A, the system will use / return the existing values.
For job B, the system will return Null as there is no values and the option is not set with a value to compute a substitute.
Energy:
For job A, the system will use / return the existing values.
For job B, the system will compute and return a substitute per core-hour value to return based on what is defined in the option (e.g. 0 in this case).
CO₂:
For job A, the system will compute and return a substitute per core-hour value to return based on what is defined in the option (e.g. 2 in this case).
For job B, the system will compute and return a substitute per core-hour value to return based on what is defined in the option (e.g. 2 in this case).
Warning
If you decide to create a cluster using an ingestion type different from FILE, please check Cluster configurations and the Timezone parameter.
Upload data
Note
The process related to the parsing and upload of data will always be handled by an asynchronous background task in the cases described below.
UI
Depending on the type of log ingestion that was selected upon cluster creation, you will be able to request a manual upload for data through different options:
Local reading of file(s):
Using the
uploadbutton on the right side of the cluster list you will have access to a form allowing you to select a file to be uploaded.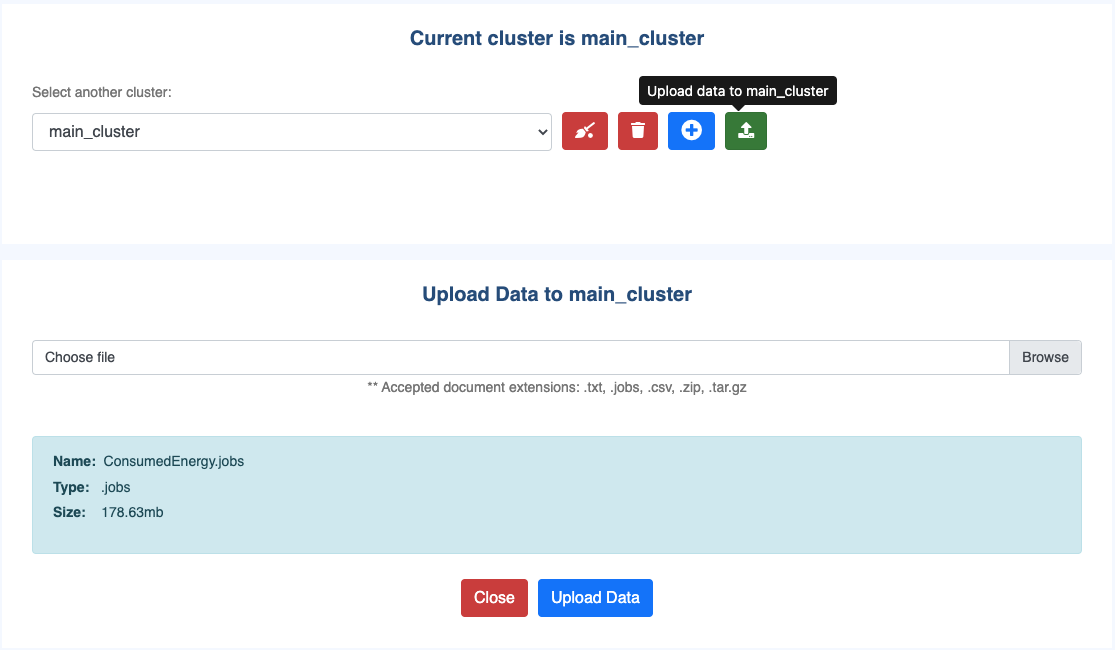
The log files you upload must be of the job scheduler type you selected during the cluster creation. You can upload either a single log file (extension
.csv,.txtor.jobs), or an archive containing multiple log files (extension.zipor.tar.gz). During this process, the given file will be stored within a temporary directory under either the default${OKA_ROOT}/data/{CLUSTER_NAME}/dir_ingestionor under a user defined folder if a different directory path has been set within theinput_file(see Conf files) configuration for this particular cluster.Local or forwarded command execution:
Using the
refreshbutton on the right side of the cluster list you will automatically start the execution of the command to retrieve the latest logs from your scheduler, parse and upload them.
Scheduled
Log ingestion can also be configured to happen automatically using scheduled tasks.
Local reading of file(s):
OKA will attempt to parse and ingest the content of all the files available at the path set within the
input_file(see Conf files) configuration for this particular cluster. The default value for this path will be${OKA_ROOT}/data/{CLUSTER_NAME}/dir_ingestion. The path can be for a single file or a directory. Files are not deleted after being ingested, it is your responsibility to handle the folder and its content as you see fit. If the available files have not changed and therefore already uploaded they will be ignored.Local or forwarded command execution:
OKA will proceed with the execution of the command to retrieve the latest logs from your scheduler, parse and upload them. By latest we mean from the last known submission date already in the database. If none yet, this will attempt to retrieve the entire history from the scheduler.
Warning
If you have data from more than a year to be retrieved we suggest to not start the retrieval in automated mode at first as it might be a really long and memory consuming process. It might be better to upload data using files month by month for example up to the current date prior to connecting your scheduler. See Retrieve job scheduler logs and contact UCit Support if you need help with this.
Delete data or a cluster
You can delete the data associated with a cluster or completely delete a cluster with the buttons on the right side of the cluster list.
Retrieve job scheduler logs
If the cluster has been configured with a FILE type of ingestion you can retrieve your job scheduler logs the following way in order to import them:
GE/SGE/OGE - Logs are stored in an
accountingfile in${SGE_ROOT}/${SGE_CELL}/common/accounting(e.g.,/usr/share/gridengine/default/common/accounting). You can either directly use this file or use the following script to retrieve it:extractSGEData.sh
#!/bin/bash ################################################################################ # Copyright (c) 2017-2023 UCit SAS # All Rights Reserved # # This software is the confidential and proprietary information # of UCit SAS ("Confidential Information"). # You shall not disclose such Confidential Information # and shall use it only in accordance with the terms of # the license agreement you entered into with UCit. ################################################################################ START="2013-01-01T00:00:00" CLEAN="yes" if [[ -z "${SGE_ROOT}" ]] || [[ -z "${SGE_CELL}" ]]; then GEACCTFILE="/usr/share/gridengine/default/common/accounting" else GEACCTFILE="${SGE_ROOT}/${SGE_CELL}/common/accounting" fi CURDATE=$(date "+%Y-%m-%dT%H:%M:%S") FILENAME="$(hostname)_${CURDATE}" TARBALL=0 set -a function unkownName() { local _prefix="$1" local _name="$2" # is name in dict? local _dictname _dictname=$(grep -e "^${_name}=${_prefix}.*" "${tmpdictfile}" | awk -F '=' '{print $2}') if [[ -z "${_dictname}" ]]; then namecount=$(grep -e "${_prefix}=.*" "${tmpcntfile}" | awk -F '=' '{print $2}') namecount=$((namecount+1)) safeid="${_prefix}_${namecount}" echo "${_name}=${safeid}" >> "${tmpdictfile}" echo "${_prefix}=${namecount}" > "${tmpcntfile}" else safeid="${_dictname}" fi } function getuid() { local _begline="$1" local _name="$2" local _endline="$3" safeid=$(id -u "${_name}" 2>/dev/null) rv=$? if [[ ${rv} -ne 0 ]] || [[ -z "${safeid}" ]]; then unkownName "unknownuser" "${_name}" fi echo "${_begline}${safeid}${_endline}" } function getgid() { local _begline="$1" local _name="$2" local _endline="$3" safeid=$(getent group "${_name}" 2>/dev/null | cut -d: -f3) rv=$? if [[ ${rv} -ne 0 ]] || [[ -z "${safeid}" ]]; then unkownName "unknowngroup" "${_name}" fi echo "${_begline}${safeid}${_endline}" } while [[ $# -ge 1 ]]; do key="$1" case ${key} in -s|--start) START="$2" shift # past argument ;; -a|--all) CLEAN="no" ;; -c|--clean) CLEAN="yes" ;; -f|--file) GEACCTFILE="$2" shift ;; -o|--output) FILENAME="${2}" shift # past argument ;; -t|--tgz) TARBALL=1 ;; -h|--help) echo "$0 [-s|--start DATE_TIME] [-a|--all] [-c|--clean] [-f|--file ACCOUNTINGFILE] [-o|--output FILENAME] [-t|--tgz] [-h|--help]" echo "Extract historical data from GE, and create the following files:" echo "- ${FILENAME}.jobs: historical data on jobs" echo "- ${FILENAME}.nodes: current nodes description" echo "- ${FILENAME}.partitions: current partitions description" echo echo "-s|--start: start date and time (format: YYYY-MM-DDThh:mm:ss, default is ${START})" echo "-a|--all: print all fields" echo "-c|--clean: do not print usernames and group names (this is the default)" echo "-f|--file: path to GE accounting file (default is ${GEACCTFILE}" echo "-o|--output: output filename (extensions will be added: .job, .nodes, .partitions)" echo "-t|--tgz: create a tarball and print its path to stdout" echo "-h|--help: print this help" echo echo "\${SGE_ROOT} and \${SGE_CELL} must be set" exit 0 ;; *) echo "Unknown option: ${key}" exit 1 ;; esac shift # past argument or value done # TODO handle start and end dates # nstart=$(echo "${START}" | awk -F'T' '{print $1}') # dstart=$(date --date="${nstart}" +%s) if [[ ! -f "${GEACCTFILE}" ]]; then echo "${GEACCTFILE} accounting file does not exist." echo "Please use the -f parameter to specify the correct accounting file." exit 1 fi cp "${GEACCTFILE}" "${FILENAME}.jobs" # Replace usernames by uid, and groupnames by gid if [[ "${CLEAN}" == "yes" ]]; then tmpcntfile=$(mktemp) tmpdictfile=$(mktemp) sed -i.bak -r -e 's#([^:]*:[^:]*:)([^:]+)(.*)# getuid "\1" "\2" "\3"#e' -e 's#([^:]*:[^:]*:[^:]*:)([^:]+)(.*)# getgid "\1" "\2" "\3"#e' "${FILENAME}.jobs" rm -f "${FILENAME}.jobs.bak" rm -f "${tmpcntfile}" rm -f "${tmpdictfile}" fi if [[ "${TARBALL}" -ne 1 ]]; then echo "${FILENAME}.jobs created" fi # Gather nodes for i in $(qconf -sel); do qconf -se "${i}" >> "${FILENAME}.nodes" done if [[ "${TARBALL}" -ne 1 ]]; then echo "${FILENAME}.nodes created" fi # # Gather configuration # qconf -sconf > "${FILENAME}.conf" # Gather list of queues for i in $(qconf -sql); do qconf -sq "${i}" >> "${FILENAME}.partitions" done # Gather list of parallel environments (not exactly queues, but necessary to run // jobs) cat >> "${FILENAME}.partitions" <<EOF ## Parallel environments EOF for i in $(qconf -spl); do qconf -sp "${i}" >> "${FILENAME}.partitions" done if [[ "${TARBALL}" -ne 1 ]]; then echo "${FILENAME}.partitions created" fi if [[ "${TARBALL}" -eq 1 ]]; then tgzfiles=("${FILENAME}.jobs" "${FILENAME}.nodes" "${FILENAME}.partitions") tar --force-local -zcf "${FILENAME}.tgz" "${tgzfiles[@]}" echo "${FILENAME}.tgz" rm -f "${tgzfiles[@]}" fi
LSF/OpenLava - Logs are stored in multiple files in a
logdirdirectory in${LSB_SHAREDIR}/cluster_name/logdir.PBS/OpenPBS/Torque - Logs are stored in multiple files an
accountingdirectory, usually:for Torque:
/var/spool/torque/server_priv/accounting/for (Open)PBS:
/var/spool/pbs/server_priv/accounting/
You can either directly use these files or use the following script to retrieve them:
extractPBSTorqueData.sh
#!/bin/bash ################################################################################ # Copyright (c) 2017-2023 UCit SAS # All Rights Reserved # # This software is the confidential and proprietary information # of UCit SAS ("Confidential Information"). # You shall not disclose such Confidential Information # and shall use it only in accordance with the terms of # the license agreement you entered into with UCit. ################################################################################ START="2010-01-01T00:00:00" CLEAN="yes" TORQUEDIR="/var/spool/torque/server_priv/accounting/" PBSDIR="/var/spool/pbs/server_priv/accounting/" ACCOUNTINGDIR="" CURDATE=$(date "+%Y-%m-%dT%H:%M:%S") FILENAME="$(hostname)_${CURDATE}" TARBALL=0 set -a function unkownName() { local _prefix="$1" local _name="$2" # is name in dict? local _dictname _dictname=$(grep -e "^${_name}=${_prefix}.*" "${tmpdictfile}" | awk -F '=' '{print $2}') if [[ -z "${_dictname}" ]]; then namecount=$(grep -e "${_prefix}=.*" "${tmpcntfile}" | awk -F '=' '{print $2}') namecount=$((namecount+1)) safeid="${_prefix}_${namecount}" echo "${_name}=${safeid}" >> "${tmpdictfile}" echo "${_prefix}=${namecount}" > "${tmpcntfile}" else safeid="${_dictname}" fi } function getuid() { local _begline="$1" local _name="$2" local _endline="$3" safeid=$(id -u "${_name}" 2>/dev/null) rv=$? if [[ ${rv} -ne 0 ]] || [[ -z "${safeid}" ]]; then unkownName "unknownuser" "${_name}" fi echo "${_begline}${safeid}${_endline}" } function getgid() { local _begline="$1" local _name="$2" local _endline="$3" safeid=$(getent group "${_name}" 2>/dev/null | cut -d: -f3) rv=$? if [[ ${rv} -ne 0 ]] || [[ -z "${safeid}" ]]; then unkownName "unknowngroup" "${_name}" fi echo "${_begline}${safeid}${_endline}" } while [[ $# -ge 1 ]]; do key="$1" case ${key} in -s|--start) START="$2" shift # past argument ;; -a|--all) CLEAN="no" ;; -c|--clean) CLEAN="yes" ;; -d|--directory) ACCOUNTINGDIR="$2" shift ;; -o|--output) FILENAME="${2}" shift # past argument ;; -t|--tgz) TARBALL=1 ;; -h|--help) echo "$0 [-s|--start DATE_TIME] [-a|--all] [-c|--clean] [-d|--directory DIR] [-o|--output FILENAME] [-t|--tgz] [-h|--help]" echo "Extract historical data from Torque/PBS, and create the following files:" echo "- ${FILENAME}.jobs: historical data on jobs" echo "- ${FILENAME}.nodes: current nodes description" echo "- ${FILENAME}.partitions: current partitions description" echo echo "-s|--start: start date and time (format: YYYY-MM-DDThh:mm:ss, default is ${START})" echo "-a|--all: print all fields" echo "-c|--clean: do not print usernames and group names (this is the default)" echo "-d|--directory: path to Torque/PBS accounting directory (default is ${TORQUEDIR} for Torque, and ${PBSDIR} for PBS)" echo "-o|--output: output filename (extensions will be added: .job, .nodes, .partitions)" echo "-t|--tgz: create a tarball and print its path to stdout" echo "-h|--help: print this help" exit 0 ;; *) echo "Unknown option: ${key}" exit 1 ;; esac shift # past argument or value done nstart=$(echo "${START}" | awk -F'T' '{print $1}') dstart=$(date --date="${nstart}" +%s) version=$(pbsnodes --version 2>&1 |head -n 1 | grep pbs_version) if [[ -n "${version// /}" ]]; then # PBS ISPBS="True" else ISPBS="False" fi if [[ -z "${ACCOUNTINGDIR}" ]]; then if [[ "${ISPBS}" == "True" ]]; then ACCOUNTINGDIR="${PBSDIR}" else ACCOUNTINGDIR="${TORQUEDIR}" fi fi if [[ ! -d "${ACCOUNTINGDIR}" ]]; then echo "${ACCOUNTINGDIR} directory does not exist. Please use the -d parameter to specify the correct accounting directory." exit 1 fi echo > "${FILENAME}.jobs" for f in "${ACCOUNTINGDIR}"/[0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9];do f=$(basename "${f}") df=$(date --date="${f}" +%s) if [[ "${df}" -lt "${dstart}" ]]; then continue fi grep -E "^[0-9]{2}/[0-9]{2}/[0-9]{4}\s[0-9]{2}:[0-9]{2}:[0-9]{2};[EDA];[^;]+;.*" "${ACCOUNTINGDIR}/${f}" >> "${FILENAME}.jobs" done # Replace usernames by uid, and groupnames by gid if [[ "${CLEAN}" == "yes" ]]; then tmpcntfile=$(mktemp) tmpdictfile=$(mktemp) sed -i.bak -r -e 's#(.*user=)([[:alnum:]_-]*)(.*)# getuid "\1" "\2" "\3"#e' -e 's#(.*group=)([[:alnum:]_-]*)(.*)# getgid "\1" "\2" "\3"#e' -e 's#(.*owner=)([[:alnum:]_-]*)(.*)# getuid "\1" "\2" "\3"#e' -e 's#(.*requestor=)([[:alnum:]_-]*)(@.+)# getuid "\1" "\2" "\3"#e' "${FILENAME}.jobs" rm -f "${FILENAME}.jobs.bak" rm -f "${tmpcntfile}" rm -f "${tmpdictfile}" fi if [[ "${TARBALL}" -ne 1 ]]; then echo "${FILENAME}.jobs created" fi if [[ "${ISPBS}" == "True" ]]; then # PBS pbsnodes -a -F json > "${FILENAME}.nodes" else # Torque pbsnodes -ax > "${FILENAME}.nodes" fi if [[ "${TARBALL}" -ne 1 ]]; then echo "${FILENAME}.nodes created" fi qstat -f -Q > "${FILENAME}.partitions" if [[ "${TARBALL}" -ne 1 ]]; then echo "${FILENAME}.partitions created" fi if [[ "${TARBALL}" -eq 1 ]]; then tgzfiles=("${FILENAME}.jobs" "${FILENAME}.nodes" "${FILENAME}.partitions") tar --force-local -zcf "${FILENAME}.tgz" "${tgzfiles[@]}" echo "${FILENAME}.tgz" rm -f "${tgzfiles[@]}" fi
SLURM - Logs are accessible through
sacct. In order to simplify the log retrieval and prevent issues during parsing, we recommend that you use the following script to retrieve SLURM logs:extractSlurmData.sh
#!/bin/bash ################################################################################ # Copyright (c) 2017-2023 UCit SAS # All Rights Reserved # # This software is the confidential and proprietary information # of UCit SAS ("Confidential Information"). # You shall not disclose such Confidential Information # and shall use it only in accordance with the terms of # the license agreement you entered into with UCit. ################################################################################ START="2010-01-01T00:00:00" FORMAT="" CURDATE=$(date "+%Y-%m-%dT%H:%M:%S") FILENAME="$(hostname)_${CURDATE}" TARBALL=0 # Setup basic access to slurm bin sacct and scontrol DEFAULT_SLURM_PATH="/opt/slurm/current/bin" if ! SCONTROL=$(command -v scontrol 2>/dev/null); then SCONTROL="${DEFAULT_SLURM_PATH}/scontrol" fi if ! SACCT=$(command -v sacct 2>/dev/null); then SACCT="${DEFAULT_SLURM_PATH}/sacct" fi while [[ $# -ge 1 ]]; do key="$1" case ${key} in -s|--start) START="$2" shift # past argument ;; -e|--end) END="$2" shift # past argument ;; -b|--batch) BATCHDURATION="$2" shift # past argument ;; -a|--all) FORMAT="ALL" ;; -o|--output) FILENAME="${2}" shift # past argument ;; -p|--path) # Force specific path to look for slurm bin sacct and scontrol SCONTROL="${2}/scontrol" SACCT="${2}/sacct" shift # past argument ;; -t|--tgz) TARBALL=1 ;; -h|--help) echo "$0 [-s|--start DATE_TIME] [-e|--end DATE_TIME] [-b|--batch DAYS] [-a|--all] [-c|--clean] [-o|--output FILENAME] [-t|--tgz] [-h|--help]" echo "Extract historical data from SLURM, and create the following files:" echo "- ${FILENAME}.jobs: historical data on jobs" echo "- ${FILENAME}.nodes: current nodes description" echo "- ${FILENAME}.partitions: current partitions description" echo echo "-s|--start: start date and time (format: YYYY-MM-DDThh:mm:ss, default is ${START})" echo "-e|--end: end date and time (format: YYYY-MM-DDThh:mm:ss)" echo "-b|--batch: number of days for the batch size. Split whole duration in 'x' smaller batches to run consecutive" echo " small sacct instead of a big request." echo "-a|--all: print all fields" echo "-o|--output: output filename (extensions will be added: .job, .nodes, .partitions)" echo "-t|--tgz: create a tarball and print its path to stdout" echo "-p|--path: path to slurm bin folder where scontrol and sacct can be found" echo "-h|--help: print this help" exit 0 ;; *) echo "Unknown option: ${key}" exit 1 ;; esac shift # past argument or value done # Job states # "running states": CONFIGURING,COMPLETING,PENDING,RUNNING,RESIZING,SUSPENDED STATES=CANCELLED,COMPLETED,FAILED,NODE_FAIL,PREEMPTED,TIMEOUT,BOOT_FAIL SLURM_VERSION=$("${SCONTROL}" --version| awk '{print $2}') SV_MAJOR=$(echo "${SLURM_VERSION}" | cut -d '.' -f 1) SV_MINOR=$(echo "${SLURM_VERSION}" | cut -d '.' -f 2) # Change supported states and format depending on the version of SLURM if [[ ${SV_MAJOR} -gt 16 || ( ${SV_MAJOR} -eq 16 && ${SV_MINOR} -ge 05 ) ]]; then # supported since 16.05 STATES+=",DEADLINE" fi if [[ ${SV_MAJOR} -gt 17 || ( ${SV_MAJOR} -eq 17 && ${SV_MINOR} -ge 11 ) ]]; then # supported since 17.11 STATES+=",OUT_OF_MEMORY,REQUEUED,REVOKED" fi # Check if format=ALL requested if [[ "${FORMAT}" != "ALL" ]]; then FIELDS=$("${SACCT}" --helpformat) # Then check based on available entry on slurm what we can actually retrieve. declare -a FIELDS_ARRAY while IFS=' ' read -r -a array; do FIELDS_ARRAY+=("${array[@]}"); done < <(echo "${FIELDS}") declare -a UNWANTED_FIELDS=("User" "Group") for element in "${FIELDS_ARRAY[@]}" do if [[ ! ${UNWANTED_FIELDS[*]} =~ (^|[[:space:]])"${element}"($|[[:space:]]) ]]; then FORMAT+="${element}," fi done fi # Set sacct options depending on the version of SLURM declare -a SACCTOPT SACCTOPT=("--duplicates" "--allusers" "--parsable2" "--state" "${STATES}" "--format" "${FORMAT}") if [[ ${SV_MAJOR} -gt 14 ]]; then # supported since version 15 SACCTOPT+=("--delimiter=@|@") fi # Set END if not defined if [[ -z "${END}" ]]; then END=$(date +"%Y-%m-%dT%H:%M:%S") fi #sacct by batch or just once if [[ -n "${BATCHDURATION}" && "${BATCHDURATION}" -gt 0 ]]; then ## Compute start & end date lists # convert to seconds: START_SEC=$(date +%s --date "${START}") END_SEC=$(date +%s --date "${END}") BATCHDURATION_SEC=$((BATCHDURATION*(3600*24))) # create date lists startlist=() endlist=() # Slurm sacct works with inclusive limits [start, end] # https://rc.byu.edu/wiki/?id=Using+sacct # The algorithm does: [start, (start2-1second)], [start2, (start3-1second)], [start3, end] # Tested on Slurm 20. CUR_DATE_SEC=${START_SEC} if (( BATCHDURATION_SEC < (END_SEC-START_SEC) )); then # Batchduration is smaller than the whole duration while ((CUR_DATE_SEC < (END_SEC-BATCHDURATION_SEC) ));do CUR_DATE_SEC_FORM=$(date -d @"${CUR_DATE_SEC}" +"%Y-%m-%dT%H:%M:%S") startlist+=("${CUR_DATE_SEC_FORM}") # get end date: ((CUR_DATE_SEC+=BATCHDURATION_SEC)) ((CUR_END_DATE_SEC=CUR_DATE_SEC-1)) CUR_DATE_SEC_FORM_END=$(date -d @"${CUR_END_DATE_SEC}" +"%Y-%m-%dT%H:%M:%S") endlist+=("${CUR_DATE_SEC_FORM_END}") done fi # Add last date startlist+=("$(date -d @"${CUR_DATE_SEC}" +"%Y-%m-%dT%H:%M:%S")") endlist+=("${END}") ## Make sure not to concat previous call with new one. It needs to be handled manually. ## Otherwise, we might have multiple time the same result if we run the script with -b and ## but different duration or date leading to having multiple time the same jobs ? rm -f "${FILENAME}.jobs" ## consecutive sacct compt=-1 for i in "${startlist[@]}";do ((compt+=1)) SACCTOPTDATES=() SACCTOPTDATES+=("--starttime" "${i}" "--endtime" "${endlist[${compt}]}") if [[ ${compt} -gt 0 ]]; then SACCTOPTDATES+=("--noheader") fi "${SACCT}" "${SACCTOPT[@]}" "${SACCTOPTDATES[@]}" >> "${FILENAME}.jobs" done else SACCTOPT+=("--starttime" "${START}" "--endtime" "${END}") # TZ=UTC => For now we'll remove the timezone "${SACCT}" "${SACCTOPT[@]}" > "${FILENAME}.jobs" fi if [[ "${TARBALL}" -ne 1 ]]; then echo "${FILENAME}.jobs created" fi "${SCONTROL}" -a -o -ddd show node > "${FILENAME}.nodes" if [[ "${TARBALL}" -ne 1 ]]; then echo "${FILENAME}.nodes created" fi "${SCONTROL}" -o -a -ddd show part > "${FILENAME}.partitions" if [[ "${TARBALL}" -ne 1 ]]; then echo "${FILENAME}.partitions created" fi if [[ "${TARBALL}" -eq 1 ]]; then tgzfiles=("${FILENAME}.jobs" "${FILENAME}.nodes" "${FILENAME}.partitions") tar --force-local -zcf "${FILENAME}.tgz" "${tgzfiles[@]}" echo "${FILENAME}.tgz" rm -f "${tgzfiles[@]}" fi
Note
The above scripts retrieve more than just the .jobs files required to ingest data.
If you create the tarballs directly through the script (-t/--tgz option), you will need to remove the .nodes and .partitions files
from the tarball as they will mess with log parsing if you leave them inside.