FAQ
OKA interface
Question
Why is OKA always displaying the same data?
Answer
There are 2 possible explanations:
Caches are used to cache OKA API responses to speed up the display of data in the interface. You might need to manually clear the caches in case OKA does not refresh the data even though you know they have been updated (see Clear cache).
UI Filters are used to filter what is displayed by OKA (to show only a sub-group of jobs for example, see Filters). You might need to modify your filters to change the data displayed.
OKA Predict and MeteoCluster
Question
Why is there no data to train the models?
Answer
By default, OKA Predict and MeteoCluster models are trained on the data from the last 30 and 365 days, respectively. If your data is older, you will have to modify these filters to have data to train the models (see Predictor - Configuration).
Consumers
Question
Why is there ‘No results found’ when looking at a category/sub-category details page ?
Answer
One reason for this could be the presence of one or more ‘/’ characters within your category and/or sub-category names (i.e. for those provided using data enhancers) and/or values. We support all special characters except the ‘/’ here and using it might lead to unexpected behaviors.
Question
Why are all UIDs equal to -1 ?
Answer
UIDs should be retrieved through the ingested logs. However, if this is not the case, there will be an attempt to find the UID related to the user associated with a job using the following command
uid = getpwnam(u).pw_uid. If after this, the UID is still not found, the default-1value will be assigned. Therefore, if all your UIDs are set to-1it might be due to one of two reasons:
Missing information on your logs.
Impossibility to find UID for a user through configuration (i.e getpwnam).
To forcefully generate replacement UIDs, use the checkbox
Generate id if naninConf job scheduler.

Multi-Cluster
Question
What steps should I take to make my existing data compatible with multicluster support?
Answer
In order to fully take advantage of the multicluster functionality, documents stored in Elasticsearch indexes must contain a Cluster_UID field.
This will be used to identify the cluster the document is associated with and is essential for OKA to properly categorize and display log information within its different plugins.
This field was added for JobScheduler logs as part of OKA v2.7.0 and OKA v2.8.0 for Occupancy specific data. Logs ingested prior to those versions won’t have the required format to work properly in mutlicluster mode.
To add the missing Cluster_UID field to your existing documents, follow these steps:
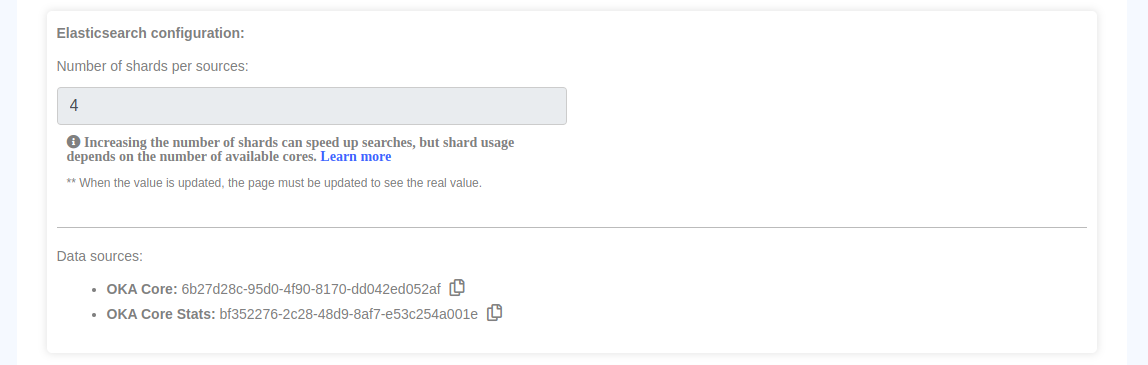
Identify required information from Management/Clusters page and OKA’s conf file:
Elasticsearch host and port: Required to access the database.
Cluster names: Required to be used as value for the new field to be created.
Index names for “OKA Core” and “OKA Core Stats”: Required to specify the indexes to update.
Save the following script as
add_cluster_uid_col.shadd_cluster_uid_col.sh
#!/bin/bash # Script to update Cluster_UID field for multiple Elasticsearch indexes # Default settings ES_HOST="localhost" ES_PORT="9200" # ======================== # EDIT THIS SECTION # ======================== # Format: "cluster_name": ["index1", "index2", ...] read -r -d '' CONFIG << 'EOF' { "cluster_name1": ["index1", "index2"], "cluster_name2": ["indexA", "indexB"] } EOF # Function to update Cluster_UID for an index add_cluster_uid_col() { local index=$1 local cluster_uid=$2 echo "Updating index '${index}' with Cluster_UID '${cluster_uid}'..." curl -X POST "http://${ES_HOST}:${ES_PORT}/${index}/_update_by_query?refresh=false&slices=auto&requests_per_second=-1" \ -H "Content-Type: application/json" \ -d "{ \"script\": { \"source\": \"ctx._source[\\\"Cluster_UID\\\"] = \\\"${cluster_uid}\\\"\", \"lang\": \"painless\" }, \"query\": { \"match_all\": {} } }" echo "" } # Process each cluster and its indexes echo "Starting cluster UID updates..." echo "${CONFIG}" | jq -c 'to_entries[]' | while read -r entry; do cluster_uid=$(echo "${entry}" | jq -r '.key') indexes=$(echo "${entry}" | jq -r '.value | .[]') echo "Processing cluster: ${cluster_uid}" # Update each index for this cluster for index in ${indexes}; do add_cluster_uid_col "${index}" "${cluster_uid}" done echo "Completed processing for cluster: ${cluster_uid}" echo "----------------------------------------" done echo "All cluster UID updates completed!"
Make the script executable:
chmod +x add_cluster_uid_col.sh
Edit the CONFIG section in the script to match your clusters and indexes
read -r -d '' CONFIG << 'EOF' { "cluster name 1": ["index-uuid-1", "index-uuid-2"], "cluster name 2": ["index-uuid-3", "index-uuid-4"] } EOF
Run the script:
./add_cluster_uid_col.sh
Important
Depending on the size of your indexes, this process can take a significant amount of time. For reference, processing approximately 10 million documents typically takes 20-25 minutes.
Reporting
Question
How would I export an analysis as a shareable report file ?
Answer
Depending on what you need to share, there are multiple options currently provided by OKA.
Exporting graphs (PNG) and datatable content (CSV, PDF etc.) is possible through exports button available individually on each graphs/datatable.
Exporting a complete page using the
Capture pagebutton at the bottom right of each page that would automatically generate a PNG of your current analysis.Generating a complete report through the use of an external script and the
pyppeteerlibrary. This option takes advantages of the fact that any plugin in OKA can be called with filtering values in the URL therefore allowing you to request any type of analysis and generating report based on your specific needs. The following configuration and python scripts are example on how this could be done.Warning
The following code is a WIP provided to you as an example of what can be done to generate a report automatically. As it is still under development, it has some limitation if used “as is”. You might need to adapt it to fit your needs.
readme
# Screenshot Automation Tool Documentation ## Overview This tool automatically captures screenshots from multiple pages in your application and combines them into a single PDF report. It works by logging into your application, navigating to each specified page, applying custom filters, and capturing full-page screenshots. ## Features - **Automated Login**: Handles authentication to access protected pages - **Multiple Page Support**: Captures screenshots from various application pages - **Custom Filtering**: Applies filters to display specific data on each page - **Interactive Elements**: Can click buttons or select dropdown options before capturing - **PDF Generation**: Combines all screenshots into a single PDF report - **Clean-up**: Removes temporary screenshot files after PDF creation ## Requirements - Python 3.9+ - Pyppeteer - Pillow ## Configuration All settings are managed in the `conf.py` file: ### Base Settings - `BASE_URL`: The root URL of your application (e.g., "http://localhost:8000") - `CREDENTIALS`: Login information (username and password) ### Default Filters (FILTERS) The `FILTERS` dictionary defines the default parameters applied to all captured pages unless overridden. These filters control what data is displayed and how it's presented: - **cluster:** Specifies which cluster's data to display. Multiple clusters can be separated by commas. - **startdate/enddate:** Define the time period for data analysis in YYYY-MM-DD HH:MM:SS format. - **multiplefilters:** Supports complex filtering with conditional logic (AND/OR operations). - **recurring_filters:** Controls time-of-day and day-of-week filtering: - **start_time/end_time:** Limit data to specific hours of the day. - **specific_days:** Limit data to specific days of the week. - **grouping_values:** Defines how data should be aggregated: - **grouping_type:** Field to group by (e.g., GID, username) - **grouping_size:** Size of groups when applicable These default filters establish baseline parameters that are applied to all pages. For generating reports with different time periods or clusters, modify these values rather than changing individual page configurations. ### Custom Filters (custom_filters) The `custom_filters` parameter allows you to override default filters for specific pages. Available also more options include: #### Category Filters - `"category": "Core_hours"` - Display core hour metrics - `"category": "Cost"` - Display cost metrics - `"category": "Power"` - Display power consumption metrics - `"category": "CO2"` - Display carbon emissions metrics #### Time Column Filters - `"datetime_col": "Submit"` - Filter by job submission time - `"datetime_col": "Eligible"` - Filter by job eligibility time - `"datetime_col": "Start"` - Filter by job start time - `"datetime_col": "End"` - Filter by job end time #### Resolution Filters - `"resolution": "1second"` - Group data in 1-second intervals - `"resolution": "1minute"` - Group data in 1-minute intervals - `"resolution": "1hour"` - Group data in 1-hour intervals (default) - `"resolution": "1day"` - Group data in 1-day intervals - `"resolution": "1month"` - Group data in 1-month intervals #### Tab Selection - `"selected_tab": "CPU"` - Display CPU-related metrics - `"selected_tab": "GPU"` - Display GPU-related metrics ### Page Configuration The `PAGE_CONFIGS` list defines each page to capture: - `path`: The URL path to navigate to - `title`: The title to display at the top of the screenshot - `custom_filters`: Specific filters that override defaults - `element_to_click`: CSS selector for buttons or links to click - `element_to_select`: Configuration for dropdown selections ### Display Settings - `ELEMENTS_TO_HIDE`: List of CSS selectors for elements to hide before capturing ### Output Settings - `PDF_SETTINGS`: Configuration for the output PDF (filename, etc.) ## How to Use 1. Ensure OKA is running and accessible 2. Update configuration in `conf.py` as needed: - Set the correct `BASE_URL` - Update `CREDENTIALS` with valid login information - Adjust `FILTERS` to capture the desired data - Modify `PAGE_CONFIGS` to capture specific pages 3. Run the script: ``` python generate_report.py ``` 4. A browser window will open (except in `HEADLESS` mode) and automatically: - Log in to the application - Navigate to each configured page - Capture screenshots - Close when complete 5. The script will generate a PDF containing all screenshots ## Customization ### Adding New Pages To add a new page to capture, add an entry to the `PAGE_CONFIGS` list: ```python { "path": "/your-page-path/", "title": "Your Page Title", "custom_filters": { "parameter1": "value1" } } ``` ### Changing Filters Modify the `FILTERS` dictionary to change default filters: ```python FILTERS = { "startdate": "2023-01-01 00:00:00", "enddate": "2023-01-31 23:59:59", # Other filters... } ``` You can first use OKA to create the filtering you want and copy&paste from the URL (or the savec filter in the Django admin panel) to get the proper values directly. ### Interactive Elements To click a button before capturing: ```python { "path": "/your-page/", "title": "Your Page", "element_to_click": ".button-class" } ``` To select a dropdown option: ```python { "path": "/your-page/", "title": "Your Page", "element_to_select": { "element": "dropdown_id", "selection": "option_value" } } ``` ## Notes - Browser visibility is controlled by the `HEADLESS` setting in `conf.py`: - `HEADLESS = False`: Browser window is visible during execution (default, good for debugging) - `HEADLESS = True`: Browser runs invisibly (better for server environments) - Screenshots are temporarily saved as PNG files before being combined into a PDF - The script waits for loading spinners to disappear before capturing screenshots
report_conf.py
# Configuration file for screenshot capture script # Base URL of the application BASE_URL = "http://localhost:8000" # Login credentials for authenticating with the application CREDENTIALS = {"login_url": f"{BASE_URL}/login/", "username": "admin", "password": "admin"} # FILTERS Configuration # Define the default data filters that will be applied to all dashboard views. # # Key parameters: # - cluster: Specifies which cluster(s) to include in reports (comma-separated for multiple "cluster a,cluster b") # - startdate/enddate: Define the time period for data analysis (YYYY-MM-DD HH:MM:SS format) # - multiplefilters: Supports complex filtering with conditional logic (AND/OR) # - recurring_filters: Controls time-of-day and day-of-week filtering # - grouping_values: Defines how data should be aggregated (e.g., by GID) # # Note: When generating reports for different time periods or clusters, modify these values # rather than changing individual page configurations FILTERS = { "cluster": "cluster a", "startdate": "2025-04-15 00:00:00", "enddate": "2025-05-15 00:00:00", "multiplefilters": {"condition": "AND", "rules": []}, "filtersprofile": {}, "recurring_filters": { "start_time": "00:00", "end_time": "23:59", "specific_days": "MONDAY,TUESDAY,WEDNESDAY,THURSDAY,FRIDAY,SATURDAY,SUNDAY", }, "grouping_values": {"grouping_type": None, "grouping_size": None}, } # Configuration for each page to capture # Each entry defines: # - path: The URL path to navigate to # - title: The title to display at the top of the screenshot # - custom_filters: Optional override filters for this specific page # - element_to_click: Optional CSS selector for elements that need to be clicked # - element_to_select: Optional dropdown selection configuration PAGE_CONFIGS = [ # KPI {"path": "/kpi", "title": "KPI"}, # Congestion {"path": "/congestion", "title": "Congestion"}, # Consumers {"path": "/consumers", "title": "Consumers", "element_to_select": {"element": "group_list", "selection": "Cluster_UID"}}, # Load # Cluster load {"path": "/load/cload-main", "title": "Cluster load"}, {"path": "/load/cload-main", "title": "Cluster load - Eligible", "custom_filters": {"datetime_col": "Eligible"}}, {"path": "/load/cload-main", "title": "Cluster load - Logarithmic", "element_to_click": 'a[data-title="Logarithmic (y)"]'}, {"path": "/load/cload-main", "title": "Cluster load - Percentage", "element_to_click": 'a[data-title="Percentage values"]'}, {"path": "/load/cload-main", "title": "Cost", "custom_filters": {"category": "Cost"}}, # Job load {"path": "/load/jload-main", "title": "Job load"}, # Resources {"path": "/resources/cores", "title": "Cores"}, {"path": "/resources/memory", "title": "Memory"}, {"path": "/resources/coresmem", "title": "Cores vs Memory"}, {"path": "/resources/nodes", "title": "Nodes"}, {"path": "/resources/gpus", "title": "GPUs"}, # State {"path": "/state", "title": "State"}, {"path": "/state", "title": "State - GID:2", "custom_filters": {"grouping_values": {"grouping_type": "GID", "grouping_size": 2}}}, {"path": "/state", "title": "State - GPU", "custom_filters": {"selected_tab": "GPU"}}, # Throughput {"path": "/throughput/jobfreq", "title": "Frequency"}, {"path": "/throughput/subtime", "title": "Submission time"}, {"path": "/throughput/waittime", "title": "Waiting time"}, {"path": "/throughput/exectime", "title": "Execution time"}, {"path": "/throughput/slowdown", "title": "Slowdown"}, ] # Browser visibility is controlled by the `headless` : # - `HEADLESS = False`: Browser window is visible during execution (default, good for debugging) # - `HEADLESS = True`: Browser runs invisibly (better for server environments) HEADLESS = False # Specify path to the browser to use BROWSER_PATH = "/usr/bin/chromium" # Settings for the output PDF file PDF_SETTINGS = {"output_path": "combined_output.pdf"} # Elements to hide before taking screenshots # These elements will not appear in the final screenshots (Add “.navbar”, to hide the navbar) ELEMENTS_TO_HIDE = [".navbar", "#sidebar", "#screenshot_button", "#djDebug", ".page_info_banner"]
generate_report.py
import asyncio import json import os import urllib.parse from conf import BASE_URL, BROWSER_PATH, CREDENTIALS, ELEMENTS_TO_HIDE, FILTERS, HEADLESS, PAGE_CONFIGS, PDF_SETTINGS from PIL import Image from pyppeteer import launch async def launch_browser(): """ Launch a browser instance for capturing screenshots. Returns: tuple: A tuple containing (browser, page) objects """ # Launch browser with visible UI (headless=False) browser = await launch(executablePath=BROWSER_PATH, headless=HEADLESS, args=["--start-maximized", "--no-sandbox", "--disable-setuid-sandbox"]) # Create a new page in the browser page = await browser.newPage() # Set viewport dimensions for consistent screenshots screen_width = 1920 # Full HD width screen_height = 1080 # Full HD height await page.setViewport({"width": screen_width, "height": screen_height}) return browser, page async def wait_for_spinner_to_disappear(page): """ Wait until loading spinner disappears from the page, ensuring content is fully loaded. Args: page: The browser page object """ while True: # Check if spinner element exists on the page spinner_exists = await page.evaluate( """ () => { return document.querySelectorAll('.overlay-spinner').length > 0; } """ ) if not spinner_exists: break # Wait briefly before checking again await asyncio.sleep(0.5) def get_url_with_filters(_url, custom_filters={}): """ Construct a complete URL with filters applied as query parameters. Args: _url (str): The base URL path custom_filters (dict): Additional filters to apply Returns: str: Complete URL with filters included as query parameters """ # Start with default filters from config filters = FILTERS.copy() # Override with any custom filters filters.update(custom_filters) # Convert dictionary values to JSON strings for key, value in filters.items(): if isinstance(value, dict): filters[key] = json.dumps(value) # Create the query string query = urllib.parse.urlencode(filters) # Add appropriate separator based on whether URL already has parameters separator = "&" if "?" in _url else "?" return f"{BASE_URL}{_url}{separator}{query}" async def add_title_to_page(page, title): """ Add a styled title heading to the top of the page for better screenshot identification. Args: page: The browser page object title (str): The title to display at the top of the page """ if title is not None: # Execute JavaScript to insert the title into the page await page.evaluate( """(title) => { const navbar = $('.navbar'); // Find the navigation bar const titleElement = `<h2 id="screenshot_title" style="text-align:center;margin:0px;font-size:24px;font-weight:bold; background-color:#f5f9ff; padding:25px;" > ${title} </h2>`; if (navbar.length > 0) { navbar.after(titleElement); // Insert after navbar } else { $('body').prepend(titleElement); // Default to inserting at the top of the body } }""", title, ) async def capture_screenshots(page_configs, credentials): """ Capture screenshots for all configured pages after logging in. Args: page_configs (list): List of configuration dictionaries for each page to capture credentials (dict): Login credentials and URL Returns: list: Paths to the saved screenshot image files """ # Initialize browser and page browser, page = await launch_browser() # Login to the application await page.goto(credentials["login_url"]) await page.waitForSelector('input[name="username"]') await page.type('input[name="username"]', credentials["username"]) await page.type('input[name="password"]', credentials["password"]) await page.click('button[type="submit"]') await page.waitForNavigation() screenshot_paths = [] # Process each page defined in the configuration for i, page_config in enumerate(page_configs): # Build the URL with appropriate filters url = get_url_with_filters(page_config.get("path"), page_config.get("custom_filters", {})) # Navigate to the target page await page.goto(url) # Wait for page to fully load (spinner to disappear) await wait_for_spinner_to_disappear(page) # Hide elements that should not appear in screenshots await page.evaluate( """ (elementsToHide) => { elementsToHide.forEach(selector => { const elements = document.querySelectorAll(selector); elements.forEach(el => { if (el) el.style.display = 'none'; }); }); } """, ELEMENTS_TO_HIDE, ) # Add title to the page for better identification await add_title_to_page(page, page_config.get("title")) # Click specified element if configured (e.g., to change view mode) if page_config.get("element_to_click") is not None: await page.evaluate( """(selector) => { const els = $(selector); if (els.length) { els.each((index, el) => { if ($(el).is(':visible')) { el.click(); } }); } }""", page_config["element_to_click"], ) await wait_for_spinner_to_disappear(page) # Select option from dropdown if specified if page_config.get("element_to_select") is not None: element_id = page_config["element_to_select"]["element"] selection = page_config["element_to_select"]["selection"] await page.evaluate( """(elementId, selection) => { // Reset any previous selections $(`#${elementId}`).selectpicker('deselectAll'); // Select the specified option $(`#${elementId} option[value="${selection}"]`).prop('selected', true); // Refresh the selectpicker to show the changes $(`#${elementId}`).selectpicker('refresh'); // Trigger the change event to execute any onchange handlers $(`#${elementId}`).trigger('change'); }""", element_id, selection, ) await wait_for_spinner_to_disappear(page) # Capture the screenshot screenshot_path = f"screenshot{i}.png" await page.screenshot({"path": screenshot_path, "fullPage": True}) screenshot_paths.append(screenshot_path) # Small delay between screenshots await asyncio.sleep(1) # Close browser session when done await browser.close() return screenshot_paths def combine_images_to_pdf(image_paths, output_pdf_path): """ Combine multiple screenshot images into a single PDF document. Args: image_paths (list): List of paths to image files output_pdf_path (str): Path where the PDF should be saved Returns: bool: True if PDF was created successfully, False otherwise """ try: images = [] for path in image_paths: image = Image.open(path) # Convert to RGB if the image is in RGBA mode (PDF doesn't support alpha channel) if image.mode == "RGBA": image = image.convert("RGB") images.append(image) if images: # The first image is used as the base, other images are appended as new pages first_image = images[0] remaining_images = images[1:] if len(images) > 1 else [] first_image.save(output_pdf_path, "PDF", resolution=100.0, save_all=True, append_images=remaining_images) print(f"Images have been combined into a PDF and saved to {output_pdf_path}") return True except Exception as e2: print(f"Error with PIL conversion: {e2}") return False def delete_image_files(image_paths): """ Delete temporary screenshot files after they've been combined into a PDF. Args: image_paths (list): List of paths to image files that should be deleted """ for path in image_paths: try: os.remove(path) except Exception as e: print(f"Error deleting file {path}: {e}") async def main(): # Capture all screenshots in a single browser session screenshot_paths = await capture_screenshots(PAGE_CONFIGS, CREDENTIALS) # Combine all screenshots into one PDF pdf_created = combine_images_to_pdf(screenshot_paths, PDF_SETTINGS["output_path"]) # Delete temporary image files if PDF was created successfully if pdf_created: delete_image_files(screenshot_paths) print("All temporary image files have been deleted.") else: print("PDF creation failed. Temporary image files were not deleted.") # Run the script when executed directly if __name__ == "__main__": asyncio.get_event_loop().run_until_complete(main())